Humanoid Locomotion as Next Token Prediction
We cast real-world humanoid control as a data modeling problem over a large collections of sensorimotor trajectories. Like in language, we train a general transformer model to autoregressively predict shifted input sequences. In contrast to language, the nature of data in robotics is different. It is high-dimensional, contains multiple sensory modalities, and actions. We tokenize the input trajectories and train a causal transformer model to predict shifted tokens. Importantly, we predict complete input sequences, including both sensory and action tokens. In other words, we are modeling the joint data distribution as opposed to the conditional action distribution.
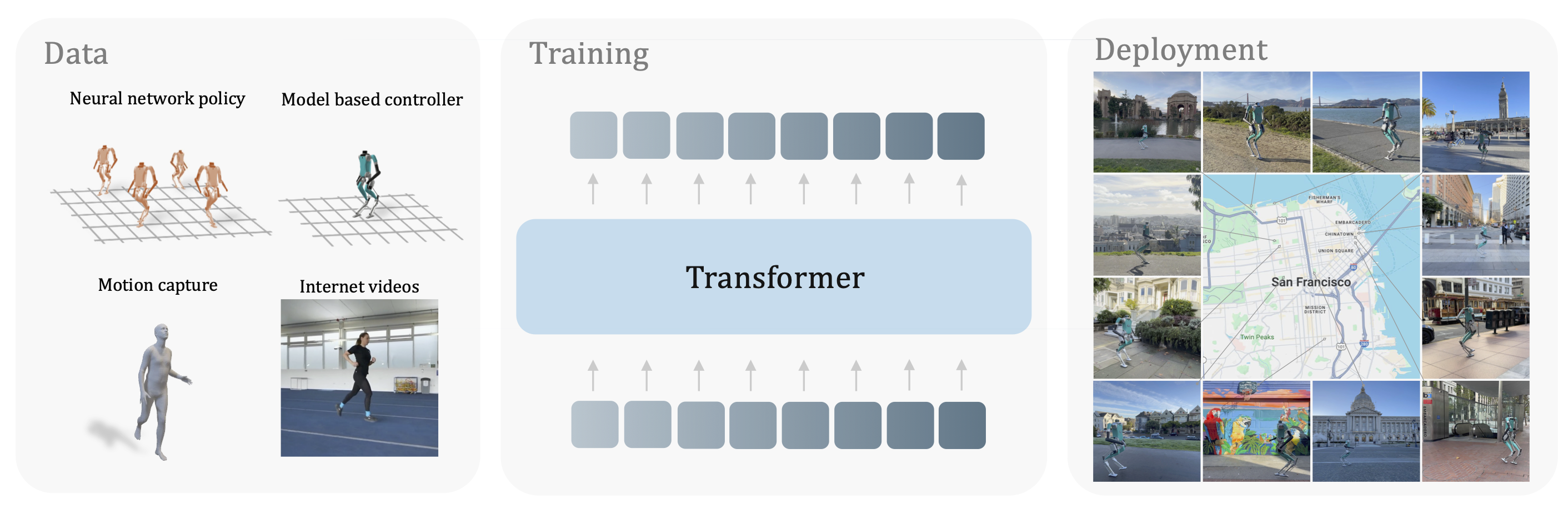
We collect a dataset on trajectories, train a transformer model by autoregressive prediction, and deploy it in San Francisco zero-shot.
A General Framework for Training with Missing Data
In the discussion so far we have assumed that each trajectory is a sequence of observations and actions. Next, we show how our framework can be generalized to sequences with missing modalities, like trajectories extracted from human videos that do not have actions. Suppose we are given a trajectory of observations without the actions. Our key insight is that we can treat a trajectory without actions like a regular trajectory with actions masked. This trajectory now has the same format as our regular trajectories and thus can be processed in a unified way. We ignore the loss for the predictions that correspond to the masked part of inputs.
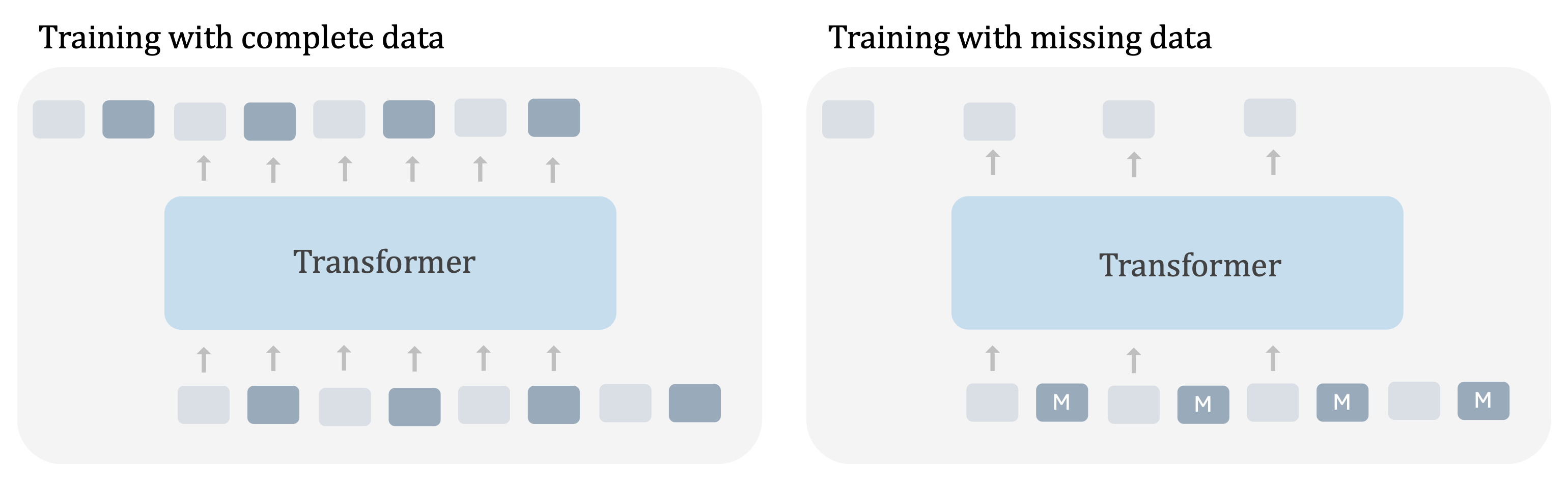
Our approach enables us to leverage trajectories with or without actions in a unified way.
A Dataset of Trajectories
Our approach motivates building a dataset of trajectories for training our model. Our dataset includes trajectories from four different sources: (i) prior neural network policies, (ii) model-based controllers, (iii) human motion capture, and (iv) human videos from YouTube. An illustration of different data sources is shown below. Different sources strike a different tradeoff between the richness of information and scale. For example, trajectories from neural network policies provide complete information including the actions. Trajectories from the model-based controller contain observations from the same robot morphology without the actions. MoCap trajectories of humans come from a different morphology without the actions. Finally, trajectories recovered from YouTube videos of humans can be seen as large scale but noisy MoCap.
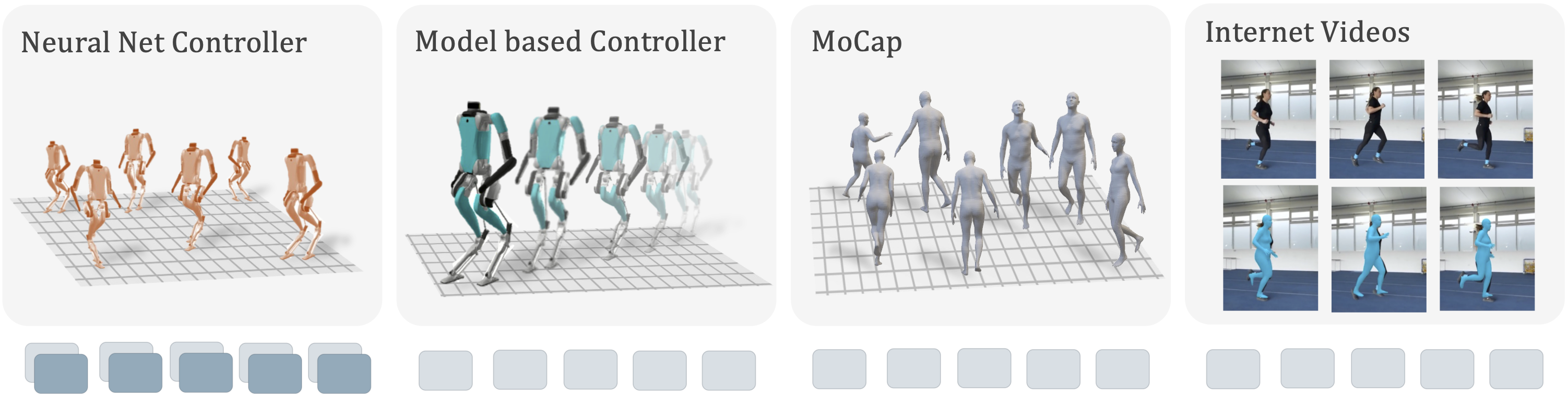
To train our model, we construct a dataset of trajectories coming from four different sources.
A Humanoid that Walks in San Francisco
We deploy our policy to various locations in San Francisco over the course of one week. A few example videos are shown below. We find that our policy can walk over different surfaces including walkways, concrete, asphalt, plazas, and sanded roads. We find that our policy follows omnidirectional velocity commands well, and enables deployment in a challenging city environment.
Walking in different locations in San Francisco
BibTeX
@article{TokenHumanoid2024,
title={Humanoid Locomotion as Next Token Prediction},
author={Ilija Radosavovic and Bike Zhang and Baifeng Shi and Jathushan Rajasegaran and Sarthak Kamat and Trevor Darrell and Koushil Sreenath and Jitendra Malik},
year={2024},
journal={arXiv:2402.19469}
}